原文: Create Multi-threaded Apache Kafka Consumer
1. 为什么需要多线程
假设我们实现了一个通知模块允许一些用户通过这个模块订阅一些来自其他用户..其他应用的通知. 我们的模块所读取的就是其他用户或应用写入到 Kafka 集群的消息. 这个例子里面, 我们将创建一个消费者订阅 Kafka 的主题来实现.
期初, 所有的事情看起来都还不错. 然而, 当其他用户和应用产生通知的数量逐渐增多, 消息增加的速度已经超过了我们的模块处理的速度时, 会发生什么呢?
好吧, 所有的事情还 … 不坏. 我们的模块处理已经不能处理所有的消息/通知, 不过这些消息还存留在 Kafka topic 中. 可是, 当消息的数量越来越多, 事情变得危险了起来, 当达到数据保留策略的设置, 一些消息可能会丢失(指的是 Kafka 的数据保留策略, 可能是基于时间, 基于数据量, 基于 key 等). 而更重要的是, 我们的消息通知模块处理的消息已经被新增的消息甩得很远, 已经完全不是一个”消息通知”模块了.
是时候考虑一下多线程消费模式了.
2. 多线程消费 Kafka 模型
有两个可能的模型.
- 多个消费者 + 多线程, 每个消费者都拥有自己的线程 (Model #1)
- 单个消费者 + 多个任务处理线程
这两个模式都有各自的优缺点:
2.1 Model #1. 多个消费者 + 多线程
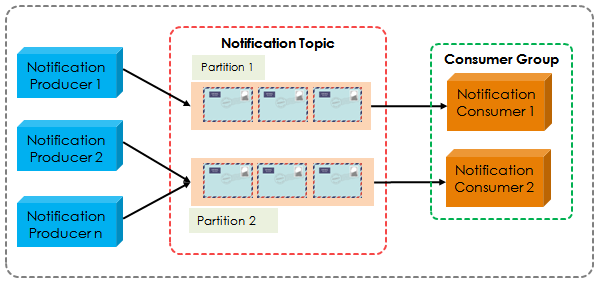
| 优点 | 缺点 |
|---|---|
| 易于实现 | 消费者数量受限于主题的分区数量, 超过分区数量的消费者可能不工作 |
| 在每个分区上实现有序处理更容易。 | 会有多个 TCP 连接到 brokers 上 |
2.2 Model #2. 单个消费者 + 多个工作处理线程
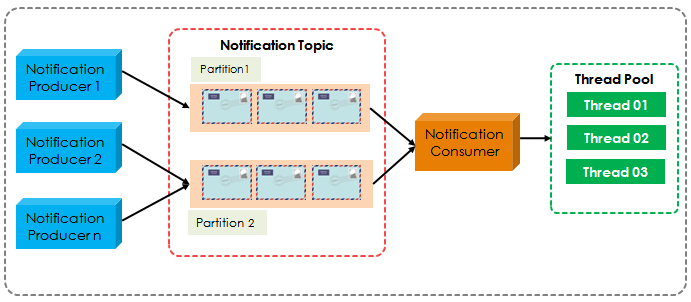
| 优点 | 缺点 |
|---|---|
| 可灵活调整任务线程的数量 | 每个分区上实现有序处理很难. 假设同一分区上有2条消息由2个不同的线程处理。为了保证顺序,这两个线程必须以某种方式进行协调。(Let’s say there are 2 messages on the same partitions being processed by 2 different threads. To guarantee the order, those 2 threads must be coordinated somehow.) |
3. 实现
接下来我们详细介绍一下这两种实现.
3.1 准备
- Kafka 已经安装
- JDK 7/8 已经安装
- Eclipse
- Maven 3
3.2 源码
原发放在了 Github 上, 可以从 这里 拉取, 也可以从 这里 下载.
源码中包含了前面提到的两个模式的实现
Model #1 在 com.howtoprogram.kafka.multipleconsumers 包里面
Model #2 在 com.howtoprogram.kafka.singleconsumer 包里面.
3.3 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0
http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.howtoprogram</groupId>
<artifactId>kafka-multithreaded-java-example</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>Kafka-MultiThread-Java-Example</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.1</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
我们使用了 kafka-clients-0.9.0.1 库来实现这个例子, Java 版本为 1.8
4 Conclusion
We have taken a look at how to create multi-threaded Apache Kafka consumer with 2 possible models. They have their own pros and cons and depend on the specific circumstance we will decide which one is suitable. Maybe, there are some cases which the model #2 is suitable. In this case, each partition of a topic will be handled by each consumer thread. However, if the number messages for this partition is too much and the consumer fall far behind, we may need to combine both the model #1 and model #2.
Below are the articles related to Apache Kafka topic. If you’re interested in them, you can refer to the following links:
Getting started with Apache Kafka 0.9
Create Multi-threaded Apache Kafka Consumer
Apache Kafka Command Line Interface
Write An Apache Kafka Custom Partitioner
How To Write A Custom Serializer in Apache Kafka
Apache Kafka Connect MQTT Source Tutorial
Apache Flume Kafka Source And HDFS Sink Tutorial
Spring Kafka – Multi-threaded Message Consumption
« EOF »
If you like TeXt, don’t forget to give me a star ![]() .
.